Summary of a Mini-Meeting on SMP Data Management Issues
NCAR
December 1, 1999
Scott Doney, Christine Hammond, Joan Kleypas
with additional input from Keith Lindsay and Steve Worley 1
This is a draft plan
addressing several important data management issues of the U.S. JGOFS Synthesis
and Modeling Project. We invite input from both the U.S. JGOFS Steering
Committee and SMP Principle Investigators. We believe we have come
up with sound recommendations, but since all SMP PIs are required to submit
their results, we strongly recommend that each PI reads this document.
As in the past, the Planning and Data Management Office (PDMO) will try
to accommodate PIs when submitting data, but there is a limited set of
standards and formats that can be reasonably supported. Thanks in
advance for your constructive comments, which should be submitted to J
Kleypas at kleypas@ucar.edu
PURPOSE
Mark Abbott, the US JGOFS Scientific Steering Committee (SSC) chairman, recently reiterated one of the objectives of US JGOFS: to develop "a complete, high quality archive of the U.S. JGOFS data which is readily accessible to the scientific community." Most of this mini-meeting was an exploration of the various ways to provide access to SMP data and to develop a plan for setting up an SMP data management system which will meet the needs of the SMP, before the next U.S. JGOFS SSC meeting. The topic of improving the interface to the existing JGOFS data management system, particularly in light of growing requirements for cross-study synthesis, was also addressed.
The primary requirement of the SMP data system is to provide access to all data sets: synthesized data, modeled output, and associated metadata. The present JGOFS data system for the process studies, designed for smaller data volumes and primarily ASCII output, may not be adequate for the task. Desired features of an SMP system (in descending order of importance) would also enable:
1. centralized access to any SMP data set (but supporting decentralized access)
2. subsetting capability
3. ability to reformat the data to one of several different formats
4. graphical display of data
RECOMMENDED TECHNOLOGY FOR SMP DATA ACCESS
The simplest and most fail-proof option for providing data access is to store all SMP data sets at a single site, and to provide a simple Web interface with a listing/description of each data set, along with downloading capability. This will be the immediate goal of the SMP data management efforts. However, we also investigated available data access systems for their potential in enhancing access to SMP data, and recommend the following arrangement, based on a) ease of data access, b) maximizing the desired features above, and c) ease of system implementation and maintenance.
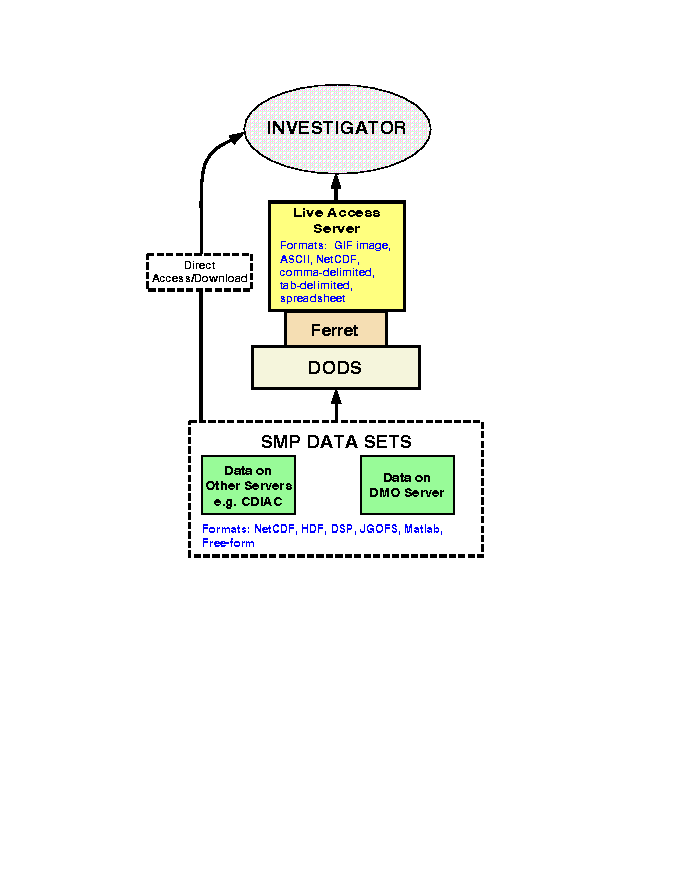
Figure 1 is a graphical representation of the recommended system arrangement, with details outlined briefly in Table 1. There are few data servers available that can handle complex data sets (e.g. 3-D spatial data of models, often with the 4th-dimension time component). However, the existing system illustrated in Figure 1 appears to be a reasonable (although perhaps not unique) fit for the SMP data user needs, and would also maintain continuity with the Ferret/Live Access Server being used at other sites that distribute carbon system data (including the ocean carbon data at GLODAP, which includes data generated by several SMP projects: http://cdiac.esd.ornl.gov/cdiac/oceans/glodap/). Each component of this system (DODS, Ferret, and the Live Access Server) is described at http://ferret.wrc.noaa.gov/Ferret/ .
Although the general recommendation is to house most of the SMP data sets on one server, some data sets would be better served remotely (i.e., via access to an existing site). A major example of this is the large scale carbon system data sets of GLODAP that are served via CDIAC. Another example is the four US OCMIP model results, each of which will likely exceed several gigabytes of data. These data sets, both because of there size and their tendency to be updated as model runs are completed, might be better accessed under a distributed data scheme. The best solution for providing access to these particular data is to use the existing DODS-based system. This system (1) gives users transparent access to data in different locations and in a variety of different formats, and (2) can translate between several common data formats (e.g. NetCDF, JGOFS, Matlab, HDF, DSP). Some common metadata attributes will need to be agreed upon so as to easily implement DODS over several data collections. The ability to bypass the system with direct download of data sets will also be provided.
Since model output from the US OCMIP runs is presently available, it
was decided that these would provide the best test case for using such
a system. The necessary steps to test this system include (1) establishing
CGD/NCAR as a DODS server and (2) setting up the DODS/Ferret/LAS system
at the WHOI Data Management site. The first step will require
coordination with the CGD systems group to ensure both adequate storage
space for the large OCMIP files, and system security. The second
step will require either additional hardware at the Data Management site
(see below), or finding a separate site where the DODS/Ferret/LAS system
can be tested.
RECOMMENDATIONS FOR JGOFS FIELD DATA SYSTEM
Several suggestions were raised considering the existing U.S. JGOFS data system for accessing field studies data. By design, these data are currently provided in a way that facilitates data usage by cruise participants. However, as the data are increasingly used by the broader scientific community, there is an expressed need to simplify data access both within and across cruises. The recommendations below are motivated by the desire to better enable data anlysis across individual variables and/or across cruises/process studies. Much thought and consideration need to be given to our priorities before allocating scarce resources to "fixing" a system which has served many for the duration of the field-study phase of US JGOFS. Discussions beyond the scope of this one day mini-meeting are needed. Scott expressed interest in presenting some of these issues to the SSC and to the Executive Scientist of US JGOFS, Ken Buesseler.
One of the first steps will be to create merged (joined) data sets collected from common platforms/samplers across all of the cruises of a process study (an example would be a common bottle file for everything collected with the rosette, a product already available for EqPac on a cruise basis). New subsetting/interface tools would then be developed for these larger, aggregated data sets similar in spirit to the tools available for the time-series.
Although many search/extract/merge capabilities exist within the current
US JGOFS data management system, these are not readily apparent to the
unfamiliar user. Also, as the US JGOFS goals shift from cruise to
cruise analyses toward larger-scale synthesis, SMP and other researchers
are requesting easier ways to access related data across several cruises
and studies. Given the current JGOFS data system structure, and the
need to retain the original data structure, most of these changes will
be facilitated through a carefully redesigned web interface that guides
users efficiently through the data extraction and access process.
FUTURE RESOURCE NEEDS
At present, the data management personnel at the Planning and Data Management Office (PDMO) consists of Christine Hammond (full time), and Dave Schneider (half-time). The major data management tasks in the near future include:
1. completion of US JGOFS Process Study field data entry and quality controlAdditional personnel will almost surely be required for the PDMO to complete these tasks. Dave's time will continue to be devoted to Task 1 above, leaving Christine to tackle the remaining tasks.
2. development of a data access system for SMP results
3. improving access to the existing US JGOFS Field Data system, and
4. archiving of Process Study data via production of CD-ROMS (one for each basin study)
Task 2 above will probably require additional hardware and disk storage
at the US JGOFS PDMO. The existing data management system for the
US JGOFS field studies resides on an SGI computer, with some auxiliary
interfacing with the GLOBEC George's Bank program's Solaris machine. Considering the recommendations
for managing SMP's diverse and high-volume data, and since the current
version of Ferret does not run on the current version of IRIX (6.5) on the DMO system, one recommendation would
be to acquire a Solaris computer to provide the two components at the top
of Figure 1 (Live Access Server and Ferret).
| COMPONENT | DESCRIPTION |
| The Live Access Server
(LAS) |
is a Web server suited to large, gridded data sets. It is built upon the Ferret program. The Live Access Server enables the Web user to visualize data with on-the-fly graphics, request custom subsets of variables in a choice of file formats, access background reference material about the data (metadata), and compare (difference) variables from distributed locations (with DODS networking) |
| Ferret | is an interactive computer visualization and analysis environment designed to for analysis of large, gridded oceanographic and meteorological data. It can transparently access extensive remote Internet data bases using DODS. |
| DODS | the Distributed Oceanographic Data System, allows users to access data anywhere from the internet using a variety of client/server methods, including Ferret. DODS supports the following data formats: NetCDF, JGOFS, HDF, DSP, Matlab, and FreeForm (most ASCII files can be handled as well). Employing technology similar to that used by the World Wide Web, DODS and Ferret create a powerful tool for the retrieval, sampling, analyzing and displaying of datasets; regardless of size or data format (although there are data format limitations). |
Figure
1. Proposed System for distributing U.S. JGOFS Synthesis and Modeling
Data